
백엔드에서 데이터를 조회할 때 성능 향상을 위해서는 캐싱 전략을 활용할 수 있습니다. 이때 어떤 방식들이 존재하고 각 방식을 구현하는 방식에 대해 알아보겠습니다.
1. 메모리 캐싱 (In-Memory Caching)
디스크 I/O 부담을 줄이기 위한 방법입니다. 자주 사용하는 데이터는 디스크(일반 DB)에 저장하지 않고 메모리에 저장하겠다는 캐싱 전략입니다. 메모리 I/O가 디스크 I/O보다 훨씬 빠르므로 이런 전략이 생겼습니다. 보통 Redis나 Memcached와 같은 인메모리 데이터 저장소를 사용해서 메모리 캐싱을 구현합니다.

2. 쿼리 캐싱 (Query Caching)
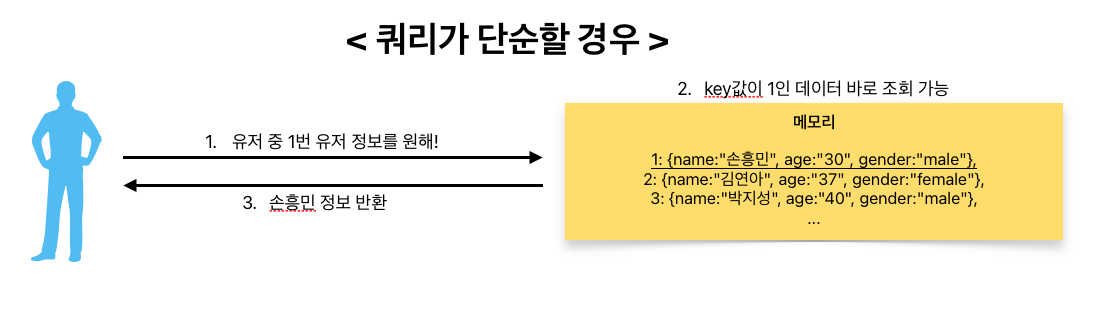
서버에서 실행되는 쿼리와 해당 쿼리가 실행되었을 때 반환되는 값을 쌍으로 메모리에 저장하는 방식입니다. 이 방법이 메모리 캐싱과 뭐가 다른지 헷갈릴 수 있는데, 그 차이는 쿼리의 복잡한 정도입니다. 예를 들어 단순히 유저 테이블의 pk값을 이용해 특정 유저를 조회하는 기능을 캐싱하고 싶다면 메모리에 key값을 유저 pk값으로 설정하고 value값은 유저 정보로 채우면 될 것입니다. 이 경우에는 key값을 이용한 빠른 조회가 가능하죠.
하지만 쿼리 자체가 복잡하다고 가정해봅니다. 나이가 10살 이상 15살 미만이고, 남성이며 몸무게는 50kg 이상이고 ... 이런 식으로 굉장히 많은 조건이 붙었다고 가정합니다. 그럼 여기서는 어떻게 해당 값을 바로 조회할 수 있을까요? 만약 바로 위에서 설정한 방식으로 메모리에 유저 정보가 존재한다면 이런 쿼리는 빠르게 동작하기가 어렵습니다. 이를 해결하기 위한 것이 바로 쿼리 캐싱이죠. 위와 같이 복잡한 조건의 쿼리를 key값으로 저장하고 이 쿼리에 대한 결과값을 value값으로 저장한다면, 해당 쿼리가 들어오면 쿼리에 대한 결과값을 바로 찾을 수 있기 때문에 성능을 향상시킬 수 있는 것이죠.

3. 데이터베이스 수준의 캐싱
데이터베이스 자체에서 캐시를 관리하도록 설정할 수도 있습니다. 예를 들어, MySQL의 경우 쿼리 캐시 기능이 있으며, 같은 쿼리에 대해 일정 시간 동안 캐시된 결과를 반환할 수 있습니다. (하지만 MySQL의 쿼리 캐시 기능은 8.0 버전부터 삭제되었습니다)
4. 분산 캐싱
분산 캐싱이란 서버가 여러 대일 때 캐시를 복제해서 여러 서버에 동일한 캐시들을 분산해서 저장한다는 개념입니다. 단순하게 캐시 복제라고 생각하면 쉽습니다. Redis에서는 이런 분산 캐싱을 cluster라는 개념을 이용해 구현합니다.
'백엔드' 카테고리의 다른 글
| [ELK] Filebeat 핵심 요약 및 설정법 (0) | 2025.02.08 |
|---|---|
| npm에서 yarn으로 갈아타기(yarn berry) (0) | 2024.11.07 |
| Kafka 카프카에 대한 이해와 간단한 실습 (0) | 2024.11.04 |
| MSA 구조 구성의 핵심: 메시지 큐(Message Queue)란? - RabbitMQ, Kafka, Redis (0) | 2024.11.04 |
| NestJS vs Spring vs Django 무엇을 사용해야할까? (0) | 2024.10.29 |