
클라우드 서비스를 이용하는 이유 중 하나는 고가용성일 것입니다. 예전에 물리적 서버를 직접 운영하던 시절에는 트래픽이 증가하면 서버실에 개발 인원이 직접 가서 물리적 서버를 한 대 더 켜야했습니다. 이런 작업은 굉장한 불편함을 발생시켰고, 현재는 클라우드 서비스의 등장으로 모두 자동화되가고 있습니다. 즉, 특정 조건이 만족되면 알아서 서버가 스케일 아웃되게 할 수 있는 것이죠. 오늘은 AWS에서 제공하는 스케이일 서비스인 Auto Scaling을 활용하는 방법에 대해 간략히 공유하겠습니다.
Auto Scaling 설정
1. 그룹 크기

최소 용량과 최대 용량만 제대로 작성하면 될 듯 싶습니다. 원하는 용량 값은 스케일 아웃, 스케일 인이 실행되면 현재 인스턴스 개수로 수정되고 있었습니다.
2. 동적 크기 조정 정책 편집

- 정책 유형
- 대상 추적 크기 조정 👍
기본적으로 스케일 아웃(늘리기)과 스케일 인(줄이기) 둘 다 동작
ex) CPU 평균사용률 60% 넘어가면 인스턴스 추가, 60% 미만이면 인스턴스 종료 - 단계 크기 조정
지표가 특정 임계값을 얼마나 초과했는지에 따라 단계적으로 인스턴스를 조정
ex) CPU 평균사용률 60% 넘어가면 인스턴스 1개 추가, 80% 넘어가면 인스턴스 2개 추가 - 단순 크기 조정
특정 조건이 한 번 만족되면 고정된 동작을 실행함
ex) CPU 평균사용률 60% 넘어가면 인스턴스 1개 추가
- 대상 추적 크기 조정 👍
- 크기 조정 정책 이름
- 지표 유형
스케일 아웃, 스케일 인에 사용할 지표(기준) - 대상 값
지표 기준 값
ex) 지표 유형에 평균 CPU 사용률로 설정한 뒤 대상 값을 50으로 정하면 CPU 평균 사용률이 50% 이상되면 스케일 아웃, 50% 이하가 되면 스케일 인 - 인스턴스 워밍업
인스턴스가 새로 생기고 나서 해당 시간 만큼은 아무런 조치를 취하지 않음. 즉, 스케일 아웃되자마자 스케일 인되는 상황 피하기 위한 설정
Auto Scaling 설정 예시
아래 내용은 실질적인 auto scaling 설정에 필요한 설정들에 관한 간단한 예시입니다.
1. 대상 그룹 추가
다음과 같이 대상 그룹을 추가합니다.

✅ 대상 유형 선택
Auto Scaling을 사용하여 EC2 인스턴스를 관리할 것이므로 '인스턴스'를 선택합니다.
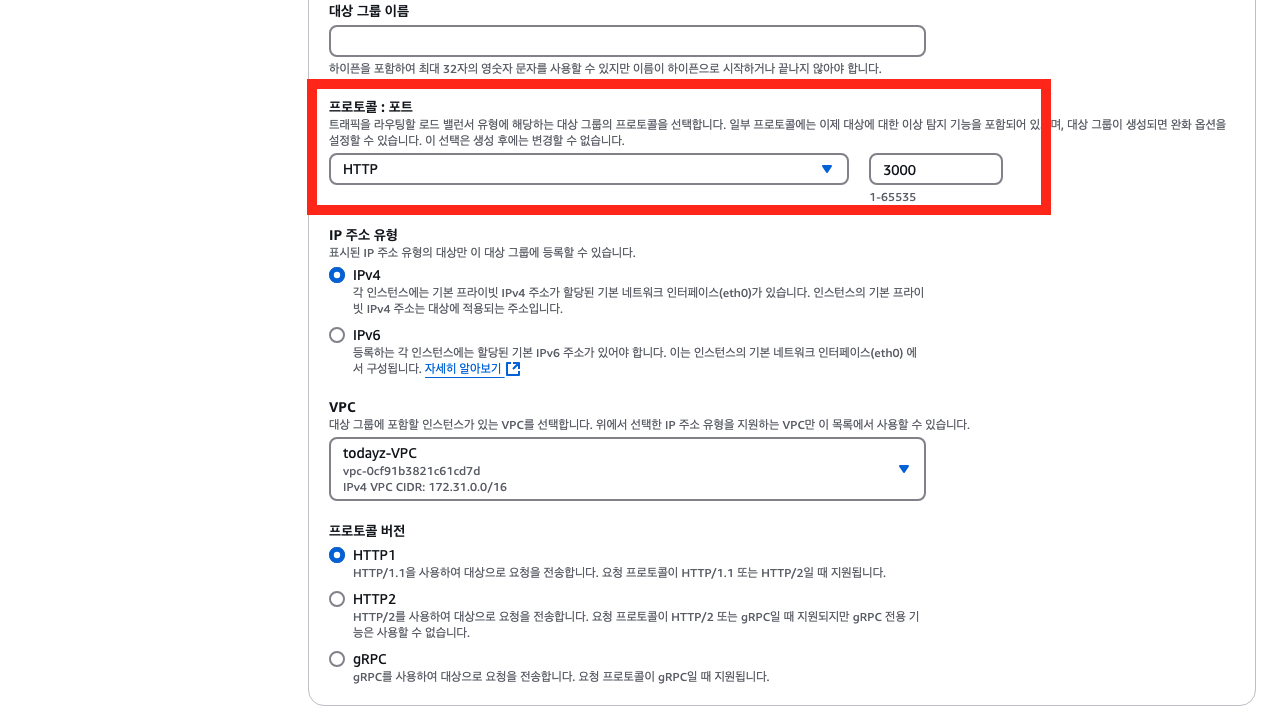
✅ 프로토콜: 포트
트래픽을 라우팅할 프로토콜과 포트입니다. 저는 EC2 내에서 3000번 포트로 NestJS 어플리케이션을 실행할 것이고 일반적인 rest api 형식으로 개발했기 때문에 HTTP 프로토콜과 3000번 포트로 설정했습니다.

✅ 상태 검사 경로
EC2 health check 하기 위한 경로입니다. 저는 NestJS에서 '/' 경로에 간단한 API를 만들어놨기 때문에 해당 경로를 헬스 체크 경로로 설정했습니다.
2. 로드 밸런서 추가
다음과 같이 로드 밸런서를 추가합니다.
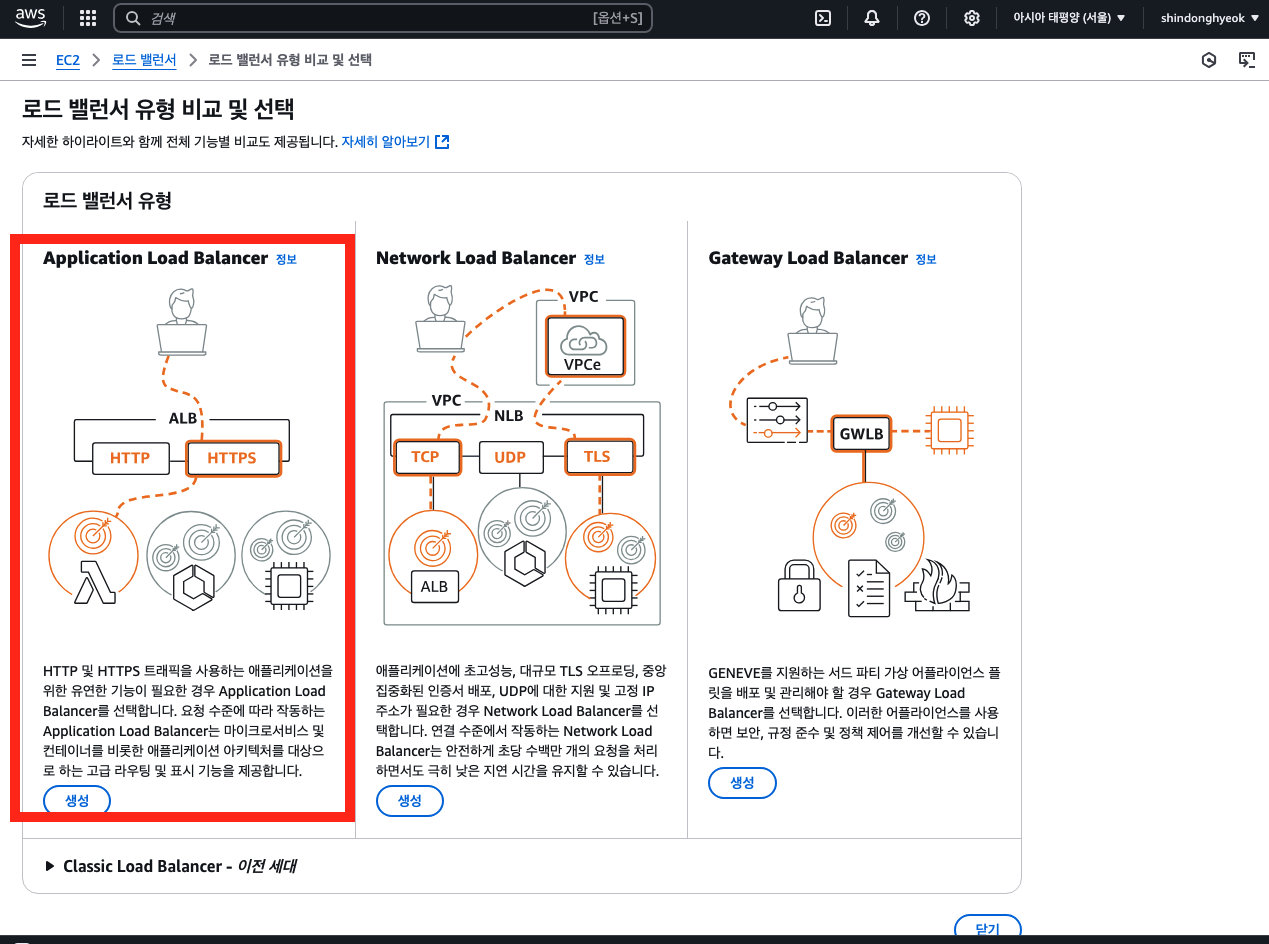
✅ 로드 밸런서 유형
로드 밸런서 유형으로 'Application Load Balancer'를 선택합니다.

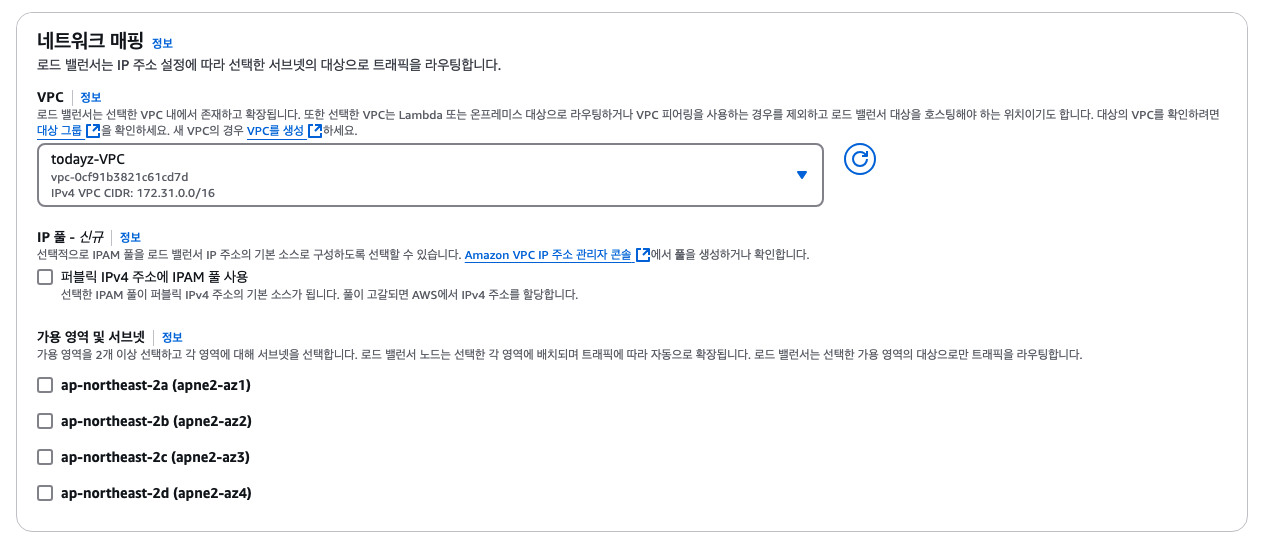
✅ 가용 영역 및 서브넷
로브 밸런스에서 트래픽 분산 범위를 정하는 것입니다. 어떤 서브넷으로 트래픽을 분산시킬지 정하는 것이죠. 이 부분은 개인의 상황에 맞게 설정합니다. 저는 모든 서브넷을 체크했습니다.

✅ 보안 그룹
보안 그룹 설정도 중요합니다. 만약 여기서 상황에 맞는 인바운드 트래픽을 허용하지 않으면 로드 밸런서 접속에 실패합니다. 저의 경우 HTTP 80포트로 접속을 시도할 것이므로 해당 인바운드 트래픽을 허용하는 설정을 추가했습니다.

✅ 리스너 및 라우팅
위에서 먼저 추가했었던 '대상 그룹'을 설정합니다. 저의 경우 HTTP 80 포트로 들어오는 트래픽을 대상 그룹으로 라우팅할 것이기 때문에 프로토콜과 포트에는 HTTP, 80 값을 넣었고 기본 작업에서는 내가 위에서 추가했었던 대상 그룹을 선택했습니다.
3. Route 53 레코드 설정
example.com 이라는 도메인을 사용한다고 가정합시다.
이때 example.com에 요청을 보내면 내가 개발한 NestJS 어플리케이션에서 응답을 하는 구조이고 이 NestJS는 EC2 인스턴스 내에서 실행 중입니다. 이때 트래픽이 증가해 여러 EC2가 생기면 example.com 이라는 도메인에 대한 요청이 알아서 여러 개의 EC2 인스턴스로 로드 밸런싱되어야 합니다. 그렇기 때문에 로드 밸런서와 연결되는 레코드가 필요합니다.

이때 레코드 유형은 CNAME, 값에는 로드 밸런서 상세 화면에서 알 수 있는 DNS 이름 값이 들어가야 합니다.
4. AMI 추가
우리가 원하는 것은 현재 실행중인 EC2 인스턴스와 동일한 인스턴스를 실행하는 것입니다. 즉, 현재 EC2 인스턴스에서 NestJS 어플리케이션이 실행되고 있고 새롭게 생긴 EC2 인스턴스에서도 NestJS 어플리케이션이 동일하게 실행되어야합니다. 그렇기 때문에 새로운 EC2 인스턴스 생성을 위해 사용할 기존 EC2 인스턴스에 대한 AMI(이미지)를 생성합니다.

5. 시작 템플릿 추가
위와 같이 AMI를 만들고 나서는, 해당 AMI를 이용해 시작 템플릿을 만들어야합니다.

6. Auto Scaling 추가
다음과 같이 Auto Scaling을 추가합니다.( 주요 설정만 소개했습니다 )

✅ 기존 로드 밸런서 대상 그룹
Auto Scaling 그룹과 연결할 로드 밸런싱 설정입니다. 위에서 추가한 '대상 그룹'을 선택합니다.

✅ 기존 로드 밸런서 대상 그룹
스케일링 정도에 대한 설정입니다. 어느 정도 개수의 EC2 인스턴스를 실행할지, 최소 개수, 최대 개수를 지정합니다. 저는 테스트를 위해 원하는 용량 1, 원하는 최소 용량 1, 원하는 최대 용량 3으로 지정했습니다.

✅ Automatic scaling
'대상 추적 크기 조정 정책' 선택 후 지표 유형 선택합니다. 저는 '평균 CPU 사용률'을 기준으로 스케일링되도록 설정했습니다. 대상 값은 퍼센트라고 생각하시면 됩니다. 평균 CPU 사용률이 50% 이상이면 스케일 아웃, 50% 미만이면 스케일 인되는 것입니다. 인스턴스 워밍업은 쿨다운 시간으로 해당 시간 동안은 스케일 아웃, 인이 되지 않습니다.
7. 테스트 및 결과
실행되고 있는 EC2 인스턴스 하나에 접속하여 강제로 부하를 올렸습니다.(저는 autocannon을 사용했습니다 ) 이를 이용해 강제로 CPU 평균 사용률을 올리자 자동으로 Auto Scaling에 따라 EC2 인스턴스가 새롭게 추가되는 모습을 확인할 수 있었습니다. 또한 새롭게 추가된 인스턴스도 Route 53와 로드 밸런서 설정으로 인해 동일한 도메인을 통해 API 요청과 응답이 정상적으로 진행되는 모습을 확인할 수 있었습니다. 또한 일정 시간 이후 CPU 평균 사용률이 낮아지자 EC2 인스턴스가 다시 종료되는 모습까지 확인할 수 있었습니다.
'데브옵스 > 클라우드 서비스' 카테고리의 다른 글
| [AWS] RDS 사용법 - 데이터베이스 생성 및 접속하기 (0) | 2025.04.03 |
|---|---|
| [AWS] 프리티어 사용 시 필수 설정 - 스왑 메모리 할당 (0) | 2025.02.08 |
| [AWS] 도메인 구매 및 등록 (0) | 2024.12.30 |